Mission Control Dispatch | Published May 7, 2026
DGX Spark image model sweep: 10 open-source generators under concurrent load
Last week we launched ten open-source image models at the same time through the public VIP path and captured the real outcome: which models finished, how long each one took, how Spark’s GPU behaved under pressure, and whether the box bent into memory pressure or snapped into transport failure.
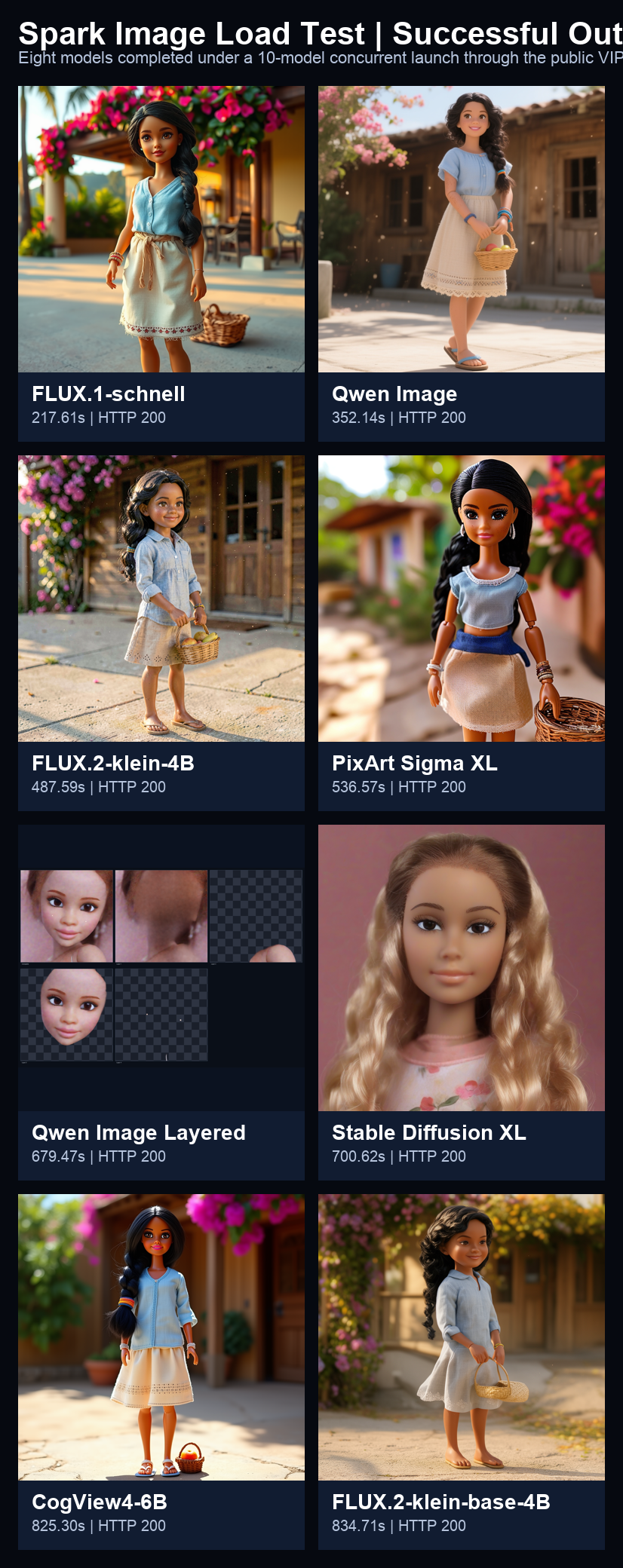
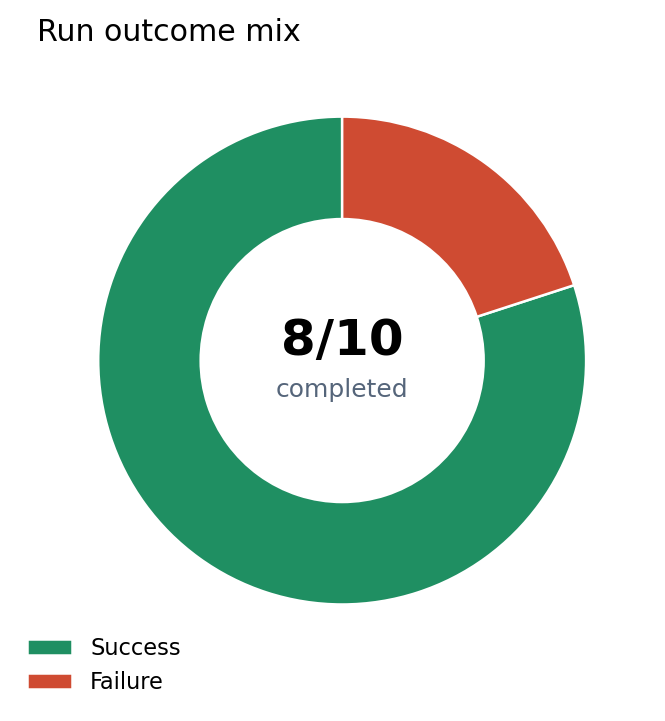
Eight models returned full images through the public chat.neonflux.co path.
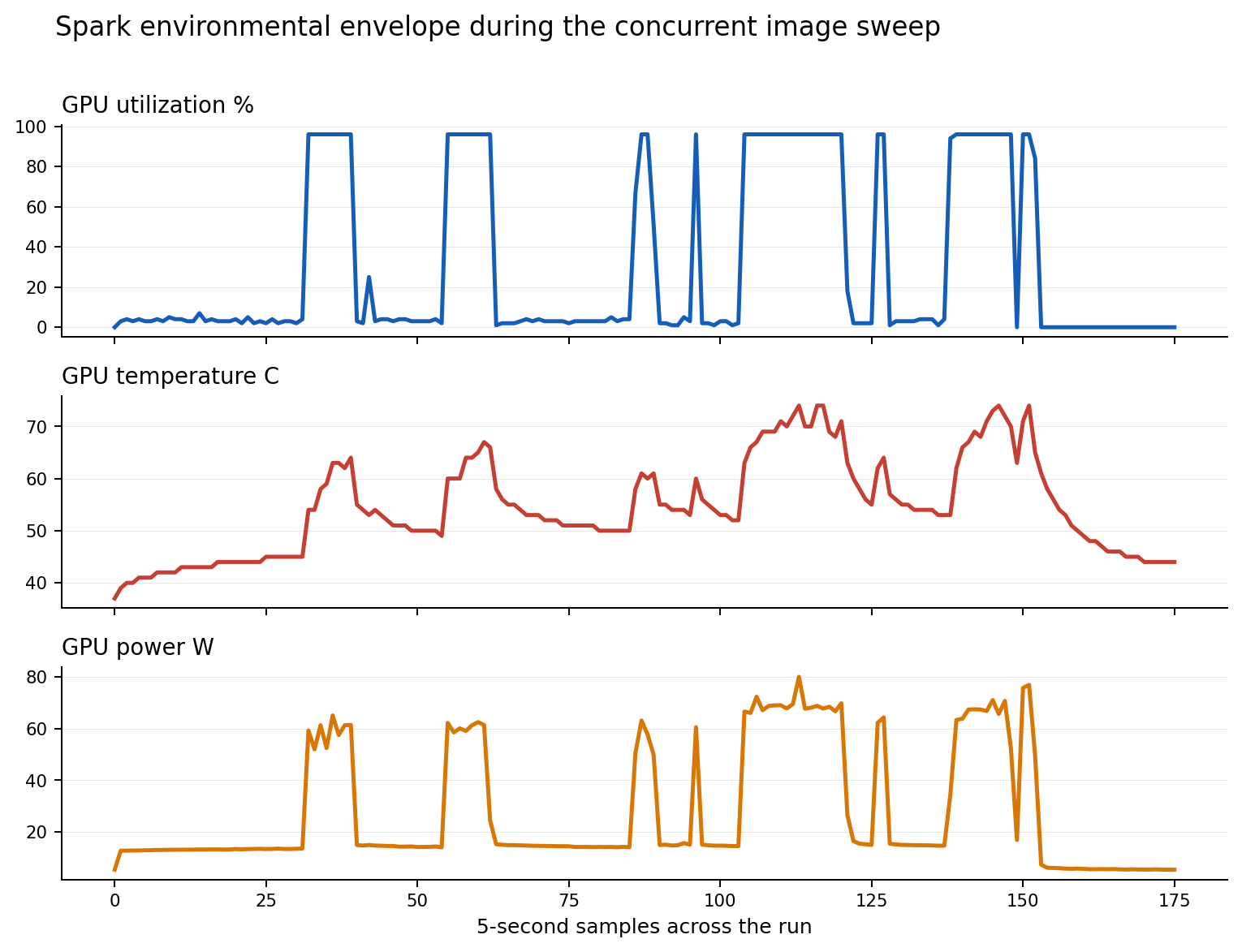
Spark heated up but stayed inside a controlled thermal envelope.
The burst pushed power sharply higher before dropping back to idle when the queue drained.
No off-the-bus, full-chip-reset, or reset-required signature was recorded in the run window.
Executive read
What the run actually proved
- DGX Spark absorbed a full 10-model image burst through the public VIP path without transport collapse, host loss, or GPU reset.
- The first real failure mode was memory pressure, not thermals and not connectivity. HunyuanDiT failed in the same window where the summary flagged
NV_ERR_NO_MEMORY. - Qwen Image Edit failed for a different reason entirely: the test did not provide a required source image, so it should not be treated as a compute-capacity failure.
- The longest successful render crossed 13.9 minutes, which means the public product should queue or tier heavy image jobs rather than pretending every model is equally fast.
Benchmark envelope
How the mission was run
| Field | Value |
|---|---|
| Path tested | http://192.168.12.163/api/chat with Host: chat.neonflux.co |
| Launch style | Ten image models fired at once in a single concurrent burst |
| Prompt class | Ultra-realistic Salvadoran character realism prompt |
| Telemetry captured | 176 Spark samples covering GPU utilization, GPU temperature, and GPU power draw |
| HTTP outcome mix | 8 successful 200 responses, 2 failed 502 responses |
The mission started at 2026-05-01T03:09:12Z, which was April 30, 2026 at 8:09 PM PDT. Because this was a simultaneous burst rather than a queue-fed run, it is a good proxy for what happens when the public surface admits too many heterogeneous image jobs at once.
Performance curves
Completion spread, failure mix, and Spark vitals
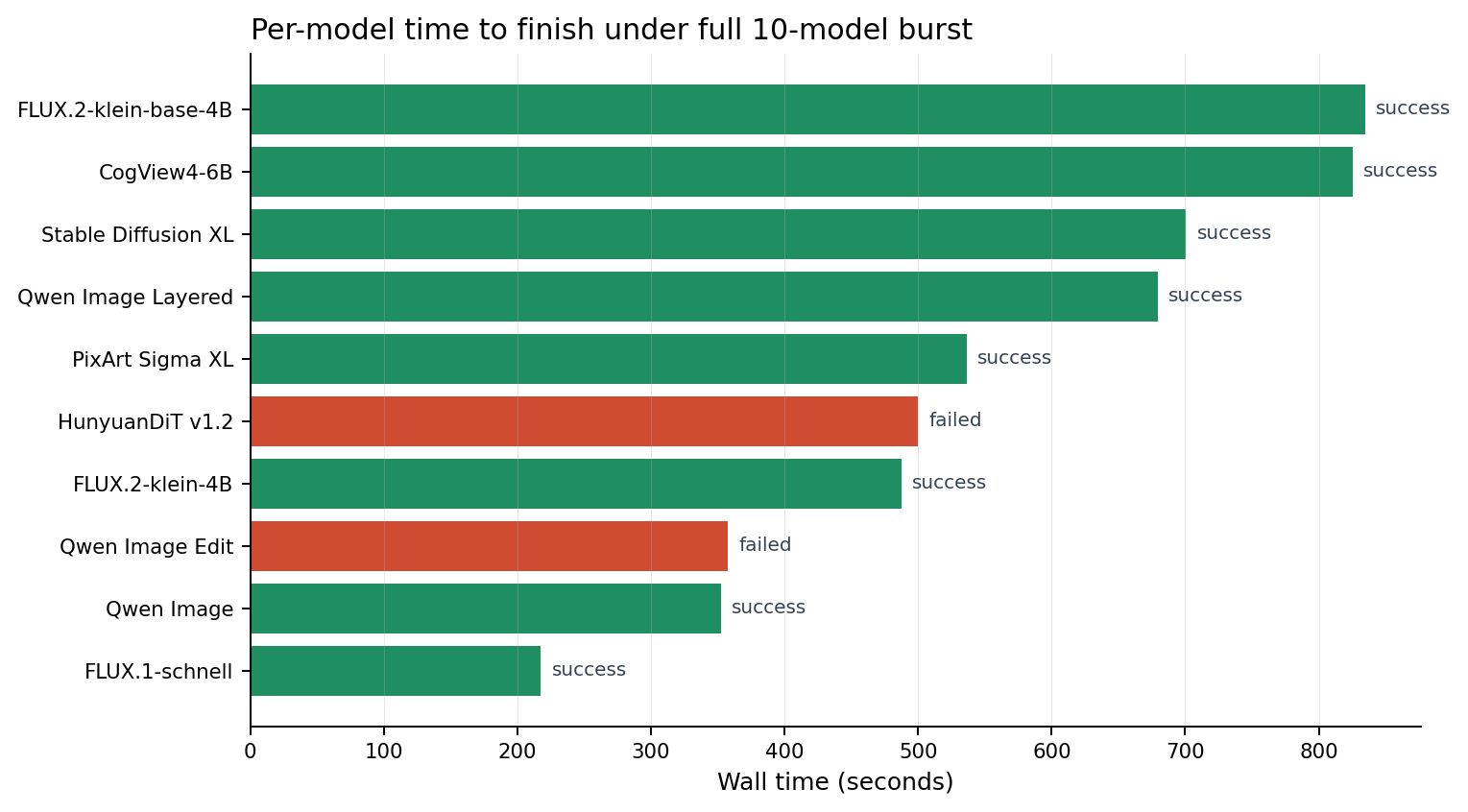
The timing spread is the real story. FLUX.1-schnell completed in a little over three and a half minutes. CogView4-6B and FLUX.2-klein-base-4B both pushed past thirteen minutes. Spark never looked sick at the transport layer, but it clearly showed that all image models are not equal tenants of the same GPU budget.
Per-model outcome table
What each model did
| Model | Status | Wall time | API latency | HTTP | Mission note |
|---|---|---|---|---|---|
| FLUX.1-schnell | success | 217.61s | 217512 ms | 200 | Fastest successful render. |
| Qwen Image | success | 352.14s | 352052 ms | 200 | Base Qwen image model completed cleanly. |
| Qwen Image Edit | failed | 357.45s | n/a | 502 | Requires source image upload. |
| FLUX.2-klein-4B | success | 487.59s | 487464 ms | 200 | Completed cleanly. |
| HunyuanDiT v1.2 | failed | 499.98s | n/a | 502 | Failure window aligned with Spark GPU memory pressure. |
| PixArt Sigma XL | success | 536.57s | 536458 ms | 200 | Completed cleanly. |
| Qwen Image Layered | success | 679.47s | 679373 ms | 200 | Completed cleanly. |
| Stable Diffusion XL | success | 700.62s | 700492 ms | 200 | Completed cleanly. |
| CogView4-6B | success | 825.30s | 825199 ms | 200 | Completed cleanly. |
| FLUX.2-klein-base-4B | success | 834.71s | 834599 ms | 200 | Slowest successful render. |
Failure analysis
Why the two misses do not mean the same thing
| Model | Failure class | What it means operationally |
|---|---|---|
| Qwen Image Edit | Input validation failure | The model requires a source image. This run did not provide one, so the failure is about request shape, not Spark capacity. |
| HunyuanDiT v1.2 | GPU memory pressure | The model failed during the same mission window where the summary recorded NV_ERR_NO_MEMORY. That is a queueing and admission-control signal, not evidence of a bus reset. |
This distinction matters. One failure says “the public surface should not expose an edit model without upload UX.” The other says “some heavy image models need a reserved lane or a queue if the site is going to admit burst traffic safely.”
Output gallery
The images that actually came back
These images were decoded from the saved response payloads captured during the benchmark. Nothing here was regenerated after the fact. The contact sheet gives the quick comparative read; the individual cards below make it easier to inspect each model’s visual signature.