
Mission Control Dispatch | Published May 7, 2026
BeastMode inference lanes: Chewbacuh vs LiL-Beastly
We moved the two BeastMode ESXi inference guests onto static 192.168.12.x service addresses, published them to the public Yeti Claw surface, and then ran the first controlled capacity benchmark through the live BeastMode route to see where each lane stays interactive and where it simply starts queueing.
Average public-path latency at concurrency 1 on qwen3:8b.
Average public-path latency at concurrency 1 on qwen3:14b.
Both lanes completed the 4-way step with zero request failures.
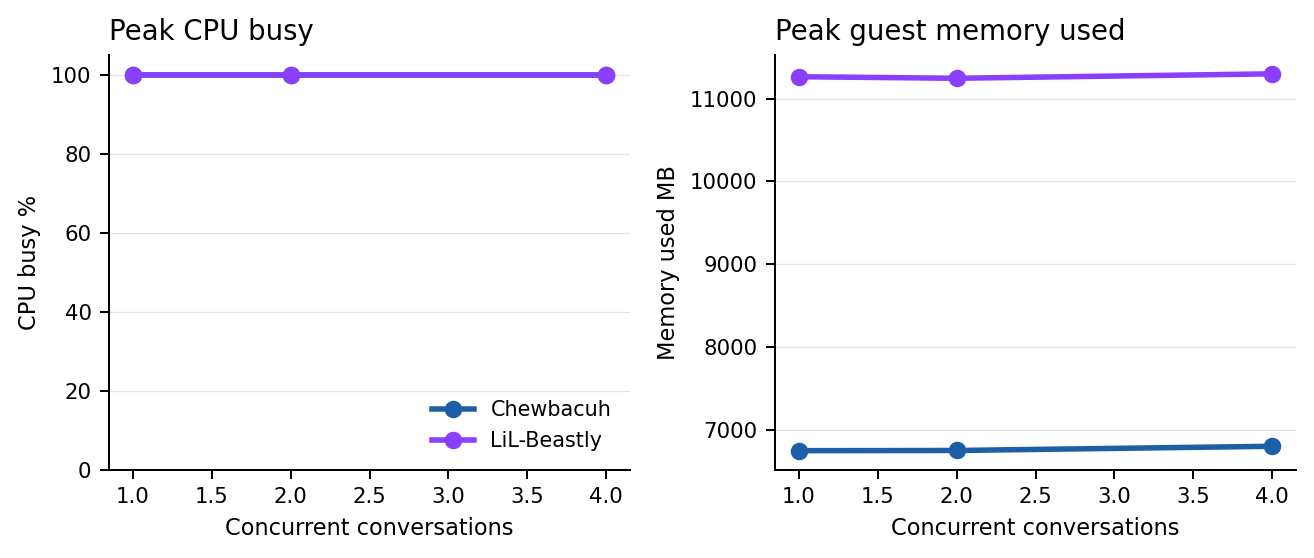
Both VMs saturated CPU on every benchmark step.
Executive read
What we learned
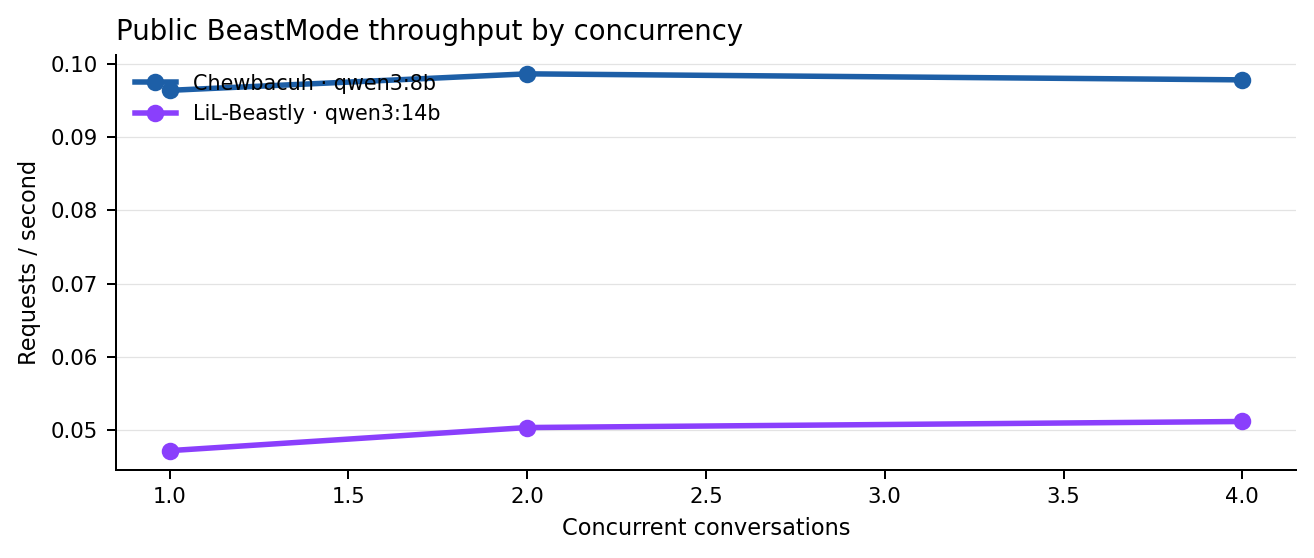
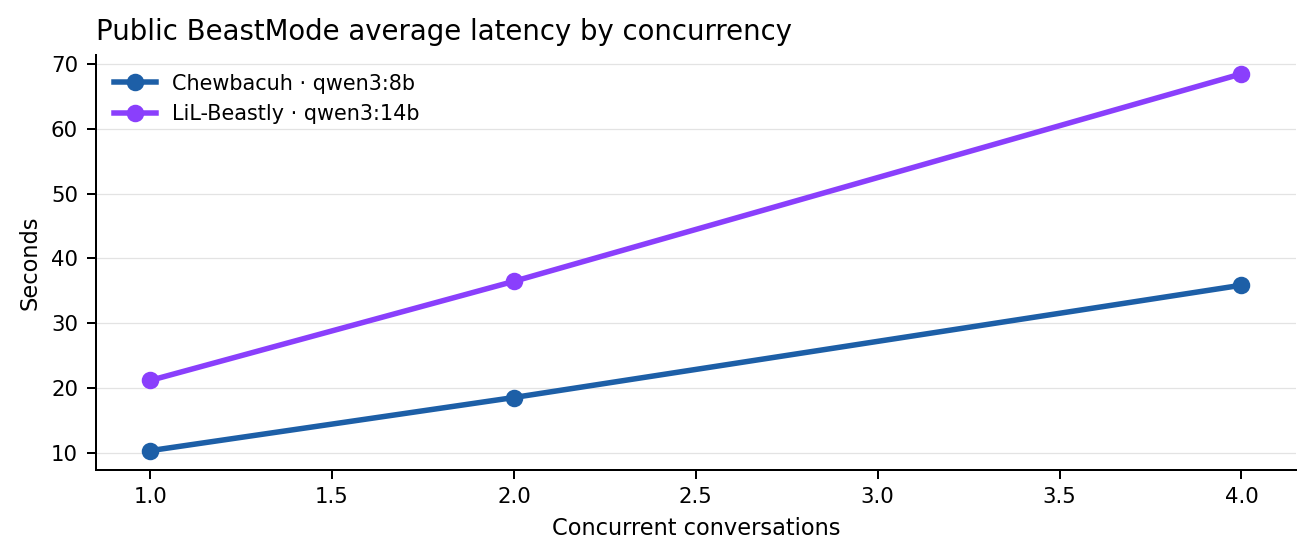
- Chewbacuh is the fast lane. It averaged 10.37 seconds at one live conversation and held throughput around 0.098 requests per second across the entire tested band.
- LiL-Beastly is the heavier lane. It averaged 21.20 seconds at one live conversation and held throughput near 0.05 requests per second across the tested band.
- Neither lane failed under load. Both completed every request through concurrency 4 with zero HTTP or inference failures.
- Both lanes became queue-bound quickly. Additional concurrency mostly increased wait time instead of increasing useful throughput.
Systems under test
Benchmark envelope and operator guardrails
| Lane | Guest profile | Model | Static service IP | Guardrail |
|---|---|---|---|---|
| Chewbacuh | 8 vCPU, 48 GiB RAM, ESXi guest | qwen3:8b | 192.168.12.173 | Controlled cap at concurrency 4 to preserve interactive access |
| LiL-Beastly | 12 vCPU, 96 GiB RAM, ESXi guest | qwen3:14b | 192.168.12.174 | Controlled cap at concurrency 4 because the 14B lane is explicitly queue-heavy |
Curve read
Throughput, latency, and guest pressure
Both BeastMode lanes saturate CPU early. The important difference is starting latency and model weight: Chewbacuh stays noticeably faster, while LiL-Beastly trades speed for the larger 14B model. Mission Control captured guest CPU, load average, and memory use. Physical temperature telemetry is not exposed reliably inside these VMs, so it is intentionally excluded from the committee findings.
Comparative table
Headline operating bands
| Lane | Tested range | Hard failures | Recommended operating band | Peak environment |
|---|---|---|---|---|
| Chewbacuh | 1-4 concurrent conversations | 0 | 1 premium / 2 acceptable / 4 queued | 100% peak CPU busy, 6.80 GiB peak guest memory used |
| LiL-Beastly | 1-4 concurrent conversations | 0 | 1 premium / 2 acceptable / 4 queued-heavy | 100% peak CPU busy, 11.30 GiB peak guest memory used |
Chewbacuh step table
Validated qwen3:8b results
| Concurrency | Success | Throughput rps | Avg latency s | P95 s | Peak CPU % | Peak load1 | Peak mem MB |
|---|---|---|---|---|---|---|---|
| 1 | 6/6 | 0.096 | 10.37 | 10.71 | 100.0 | 6.01 | 6749.2 |
| 2 | 6/6 | 0.099 | 18.56 | 20.41 | 100.0 | 7.42 | 6751.3 |
| 4 | 12/12 | 0.098 | 35.88 | 41.24 | 100.0 | 8.09 | 6802.1 |
LiL-Beastly step table
Validated qwen3:14b results
| Concurrency | Success | Throughput rps | Avg latency s | P95 s | Peak CPU % | Peak load1 | Peak mem MB |
|---|---|---|---|---|---|---|---|
| 1 | 6/6 | 0.047 | 21.20 | 24.20 | 100.0 | 11.28 | 11264.2 |
| 2 | 6/6 | 0.050 | 36.48 | 40.06 | 100.0 | 12.16 | 11245.5 |
| 4 | 12/12 | 0.051 | 68.47 | 78.62 | 100.0 | 12.28 | 11299.0 |
Operator opinion
How to use the lanes
- Route speed-sensitive public chat to Chewbacuh first.
- Reserve LiL-Beastly for prompts where the larger model is worth the higher wait time.
- Keep clear working indicators in the UI because both lanes become queue-bound before they become unstable.
- Do not market concurrency 4 as “real-time” on either lane. It is stable, but it is not snappy.