
Mission Control Dispatch | Published May 18, 2026
Spark text lane migration: Ollama to TensorRT-LLM on DGX Spark
We moved Spark’s public text lane off the legacy Ollama path and onto TensorRT-LLM, but only after documenting the failures that showed up along the way. The direct pip routes were not stable on GB10. The working production answer ended up being NVIDIA’s official NGC release container, which gave us a clean OpenAI-compatible endpoint, lower concurrency-4 latency than the old lane, and a real throughput gain under load, while sacrificing single-request speed and temporarily shrinking the public Spark text catalog to one model.
Up from 38.47 tok/s on the legacy Ollama lane under the matched c4 test.
Down from 8738.93 ms when four requests were active simultaneously.
Up from 2541.67 ms, which is the main tradeoff of the new lane.
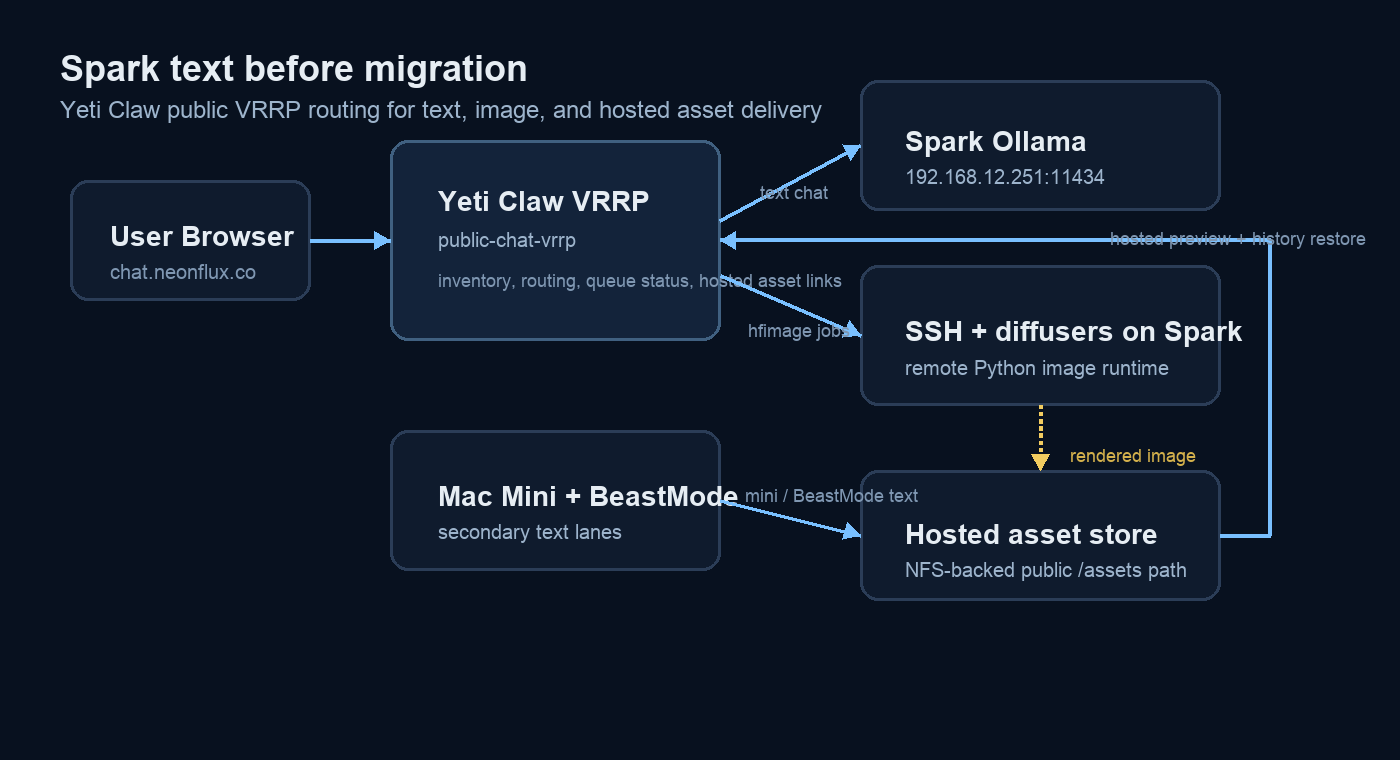
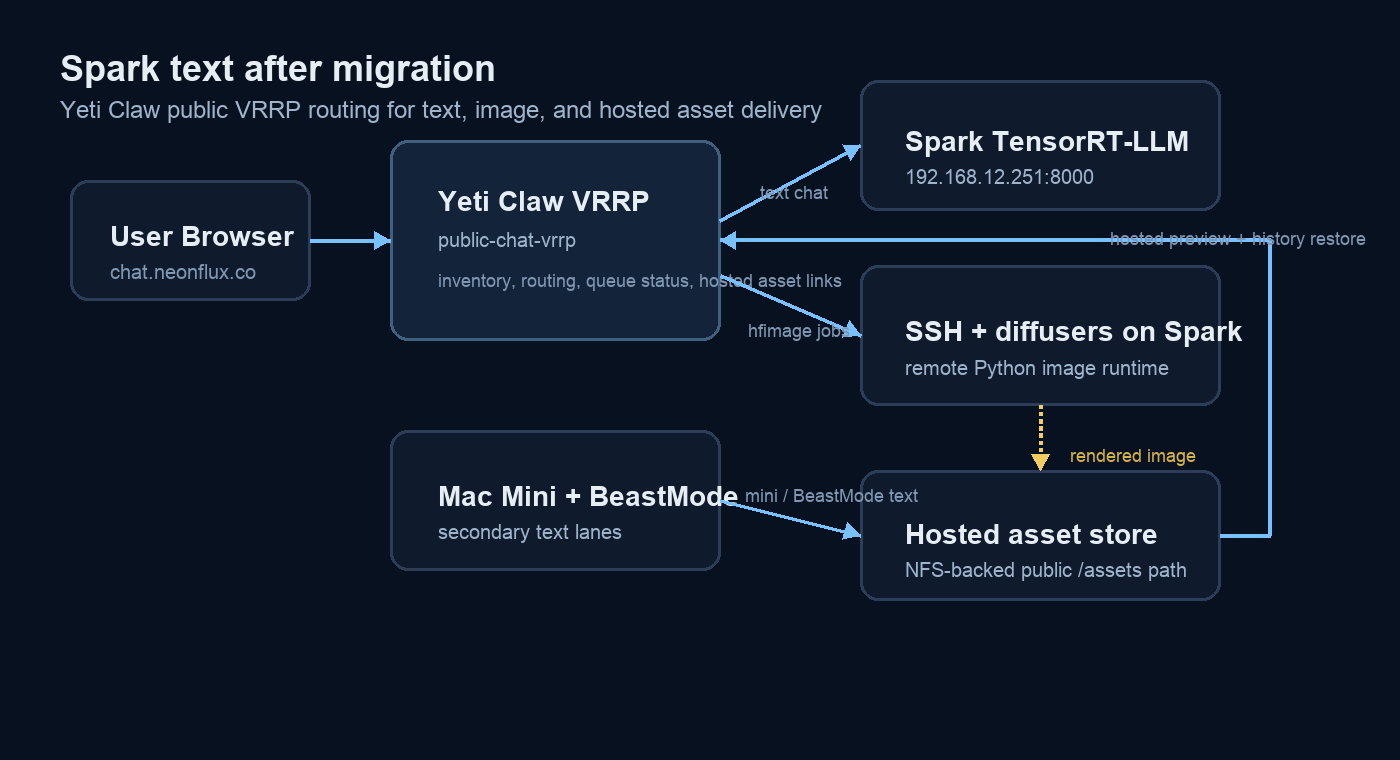
The first public cutover focuses Spark on one TRT-served Qwen3 lane instead of five mixed text entries.
Executive read
What we learned from the transition
- TensorRT-LLM on Spark is real, but the supported route is the NGC release container, not an ad-hoc pip install.
- The new text lane is slower for a single request, but it scales materially better once four requests are active.
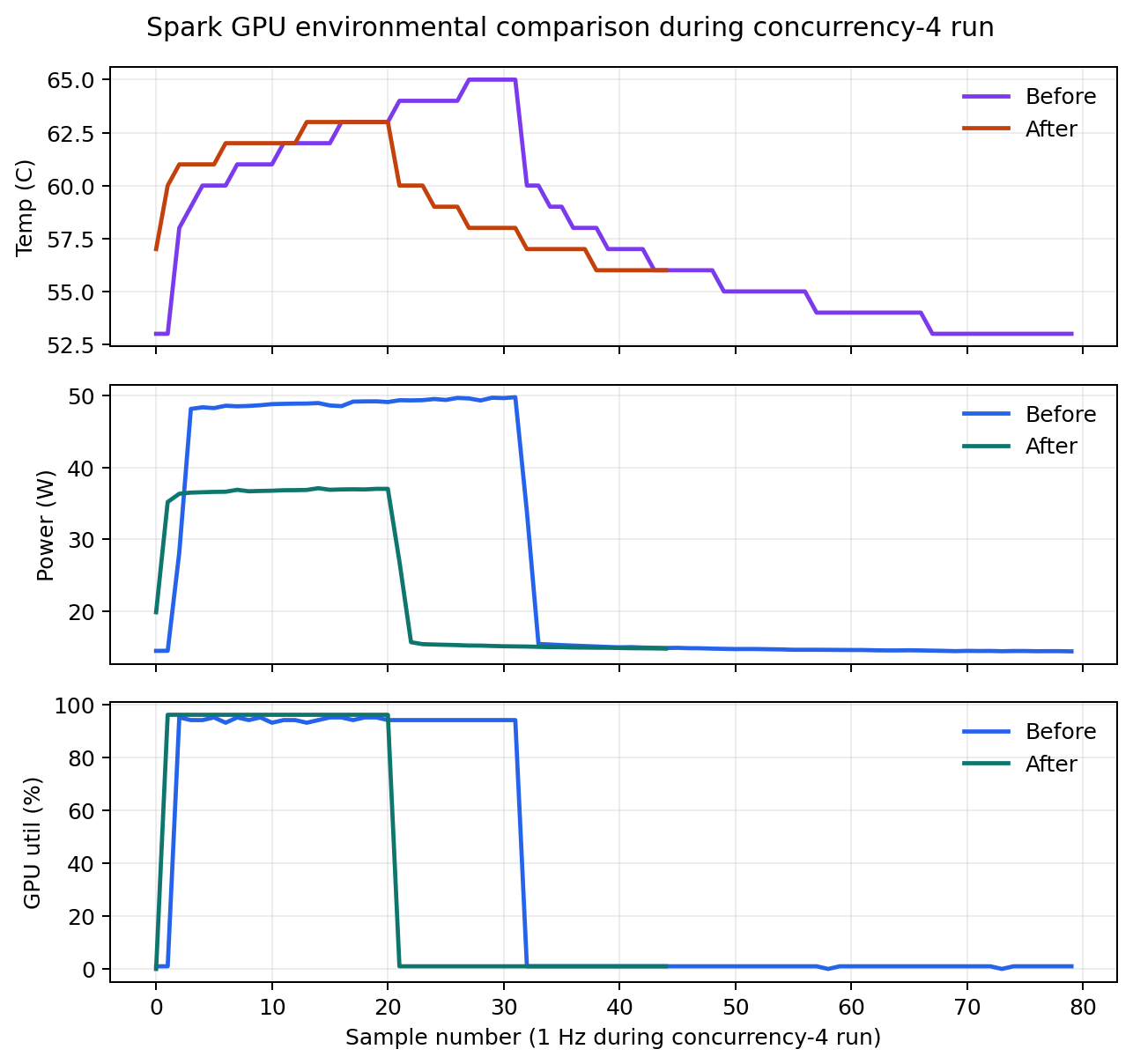
- Peak sampled GPU temperature fell from 65 C to 63 C and peak power fell from 49.73 W to 37.1 W during the matched c4 run.
- The migration does not disturb the Spark image path, which still runs through the separate hosted-image workflow.
- The price of this cleaner runtime is a narrower Spark text catalog until more TRT-served models are added.
Architecture
What changed in the public text path
Before the migration, Spark text requests shared the same Ollama lane that also exposed legacy and multimodal text inventory. After the migration, the public VRRP tier points Spark text to a dedicated TensorRT-LLM OpenAI-compatible endpoint on port 8000 while leaving the Spark image workflow untouched. That split is the cleanest part of the transition: text inference became easier to reason about operationally even though the bring-up was harder than expected.
Performance
Before-and-after numbers under matched load
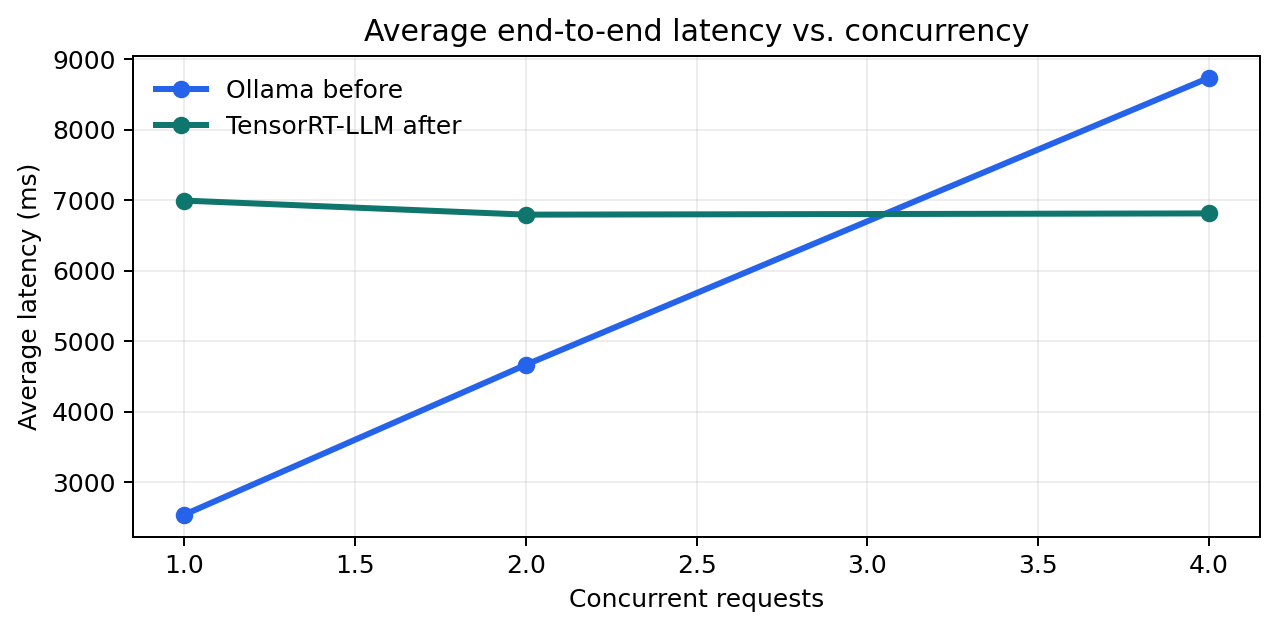
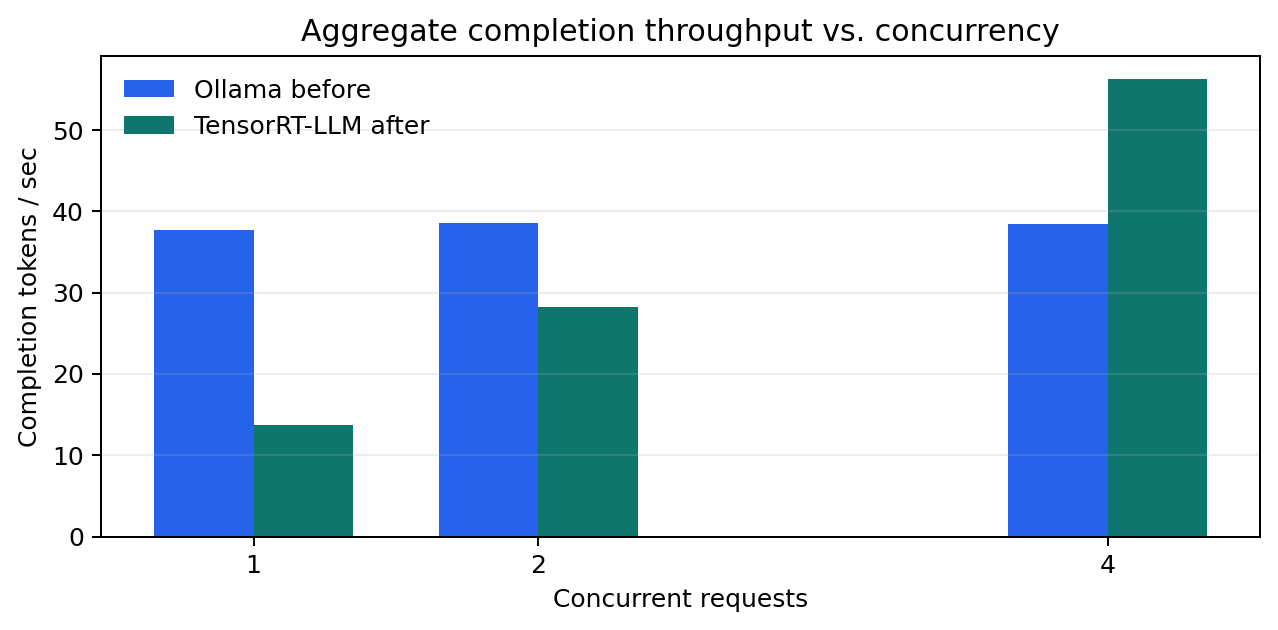
We reran the exact concurrency ladder against the same Spark hardware using the same prompt shape and the same 96-token completion cap. That gives us a fair operator comparison between the old Ollama lane and the new TensorRT-LLM endpoint. The story is mixed but clear: single-request latency regressed, concurrency-2 throughput still trails the old path, and concurrency-4 is where the new lane finally starts paying back the migration work.
| Concurrency | Before avg ms | After avg ms | Before tok/s | After tok/s | Read |
|---|---|---|---|---|---|
| 1 | 2541.67 | 6997.54 | 37.76 | 13.72 | Single-request latency is worse on the new lane. |
| 2 | 4667.74 | 6797.99 | 38.56 | 28.20 | Still slower than Ollama under light parallelism. |
| 4 | 8738.93 | 6815.54 | 38.47 | 56.29 | TRT-LLM wins once the Spark text lane is actually busy. |
Environmentals
Thermals and power held steady through the new lane
The migration did not create a new thermal problem on Spark. In the matched concurrency-4 window, GPU utilization stayed effectively saturated in both eras, while the new TRT lane sampled slightly lower peak temperature and materially lower peak power draw. That matters because it tells us the migration’s pain was software compatibility, not heat or raw platform instability.
Compatibility findings
Why the first two migration paths failed
The paper trail matters here. We did not land on the final container path by preference alone. We got there because the direct pip options failed in two different ways on Spark’s GB10 platform. The newer `1.2.x` wheel line did not import cleanly against the live CUDA/Torch packaging. The older `0.20.0` fallback could be forced to import, but then it failed at runtime with unsupported-kernel errors in FlashInfer, fused attention, and finally even the vanilla fallback path. That is exactly the kind of migration detail committees need to see so they understand what is “supported” versus merely “possible.”
- `1.2.1` pip lane: import failure around `libth_common.so` and PyTorch symbol mismatch.
- `0.20.0` pip fallback: importable only after Spark-specific CUDA shims, then failed in FlashInfer and GB10 attention kernels.
- `1.3.0rc12.post1` NGC container: successful model load, warmup, autotune, CUDA graph prep, and live `/v1/models` endpoint.
The downloadable artifact bundle includes the compatibility notes, logs, diagrams, benchmark JSON, and the PDF version of this dispatch for committee review.
Recommendation
How we should operate the Spark text lane from here
- Keep Spark text on the TensorRT-LLM release container path, not a custom pip environment.
- Treat this lane as a higher-concurrency public worker, not the fastest single-request chat surface.
- Keep the Mac mini and BeastMode lanes available for lighter or lower-latency text traffic.
- Expand Spark’s TRT-served catalog only after each additional model is benchmarked through the same Mission Control workflow.